

开发能理解人类语言的计算机
※内容在撰写本文时是最新的。
利用深度学习进行自然语言处理。
研究概况

最近,你可能经常在电视和报纸上听到人工智能和深度学习这两个词。近年来,模仿人类神经网络学习多层神经网络的研究取得了重大进展,这些不同的技术被称为深度学习。虽然人们对深度学习的理论特性还不完全了解,但认为它具有自动学习数据特征的高度抽象性,在图像识别和语音识别方面,其准确率大大超过了传统方法,达到了接近人类的分析准确率。在人类语言(自然语言)分析方面,通过深度学习获取语言概念、机器翻译和对话等技术也在被积极研究,已经实现了比传统技术更接近人类的自然语言处理。很多人可能都使用过谷歌翻译或.NET 翻译等机器翻译服务。
由 OpenAI 开发的 ChatGPT,通过使用由数十亿到数千亿个参数组成的大规模语言深度学习模型(大规模语言模型),从规模空前的自然语言数据中进行学习,从而实现了像人类一样进行交互,并在全世界引起了轰动。?这是通过使用由数十亿到数千亿个参数组成的庞大语言深度学习模型(大规模语言模型),从规模空前的自然语言数据中学习实现的。我所在的人工智能实验室也专注于这些深度学习技术,并开展声誉分析、谓词表达式获取、专有名称分析、机器翻译、情感分析和质量评估等自然语言处理方面的研究。
研究特色
我们利用深度学习技术开展自然语言处理研究。它有两个主要特点:一是以语言结构为重点的自然语言处理研究,二是符号基础研究。
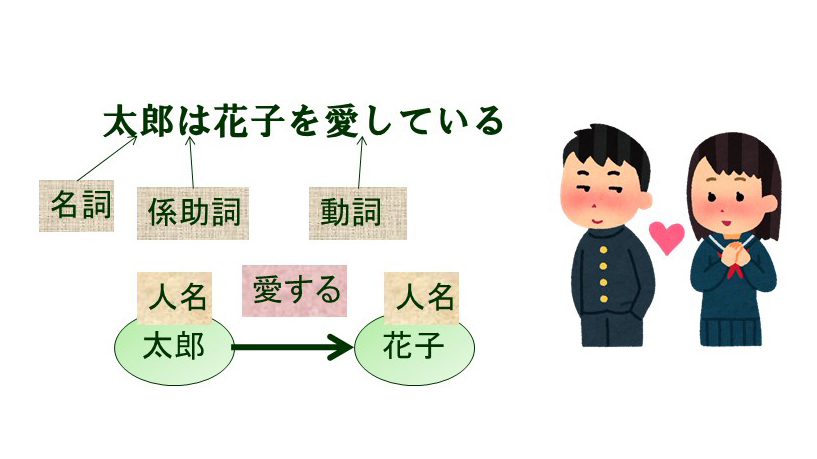
首先,语言有其特定的语言结构,语言学和其他领域已经对此进行了阐述和讨论。例如,有名词、动词和形容词等语篇,人名、地名和公司名等专有名词,考虑到这些因素的名词短语和动词短语等分句结构,主语、谓语和宾语等术语结构,表示依存关系的依存结构,以及相对从句和被动语态等各种句法结构(图 1)。通过将这些结构的分析与深度学习技术相结合,我们的目标是实现更高性能的自然语言处理。反过来,我们也在进行学习这些结构的研究。在机器翻译中,子词(即比单词短但比字母长的字符串)被用作输入,我们正在研究用于机器翻译的双语子词。
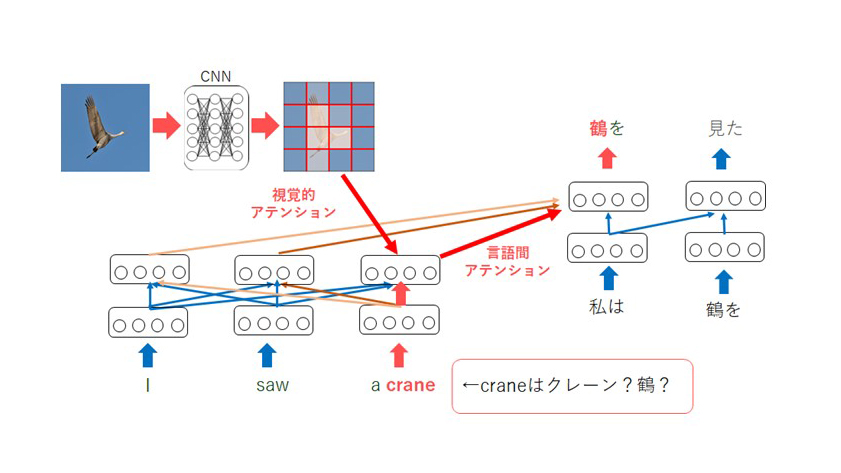
足球即时比分_365体育直播¥球探网第二项,即符号基础,传统的自然语言处理只使用文本中的符号信息进行学习,但为了实现更像人类的学习,有必要学习符号与真实世界(如图像)之间的映射(符号基础)。为了实现这些目标,我们正在研究多模态机器翻译。其目的是通过在进行机器翻译时提供图像信息来实现更好的翻译。例如,如果给出的句子是 “我看到了一只起重机”,那么 “起重机 “到底是 “鹤 “还是 “鹤 “就不清楚了。如果能同时给出一幅图像,就能解决这些歧义,将句子正确翻译为 “我看到了一只起重机”(图 2)。(图 2)。此外,机器翻译还使用一种名为注意力的技术,这种技术可应用于多模态机器翻译,以学习图像的哪些部分需要重点翻译。例如,在翻译图 3 句子中的 “人 “字时,可以看到翻译的重点是图像中的人。

除此以外,我们还开展了自动摘要、情感分析、复合名称识别、翻译质量评估、分级、语言模型学习、使用强化学习的机器翻译、自动创建英语填空问题以及使用深度学习的其他各种自然语言处理研究。
研究的吸引力
首先,当前的人工智能研究非常有趣!这就是它如此有趣的原因。深度学习热潮,也就是所谓的第三次人工智能热潮,大约始于 2012 年,但在此之前,人们都说人工智能不是很准确,需要很长时间才能实用化,而且在我们有生之年也无法实现。人工智能已有 70 多年的历史,但在过去短短十年间发展迅速。传统观念被颠覆,新技术层出不穷。我认为这是当前最令人兴奋的研究领域。过去,我们不可能研究 “意义”(我们不可能回答 “意义 “是什么这个问题),但现在我们可以看到一些看起来像意义的东西,我们还可以处理上下文。此外,通过同时学习文本信息和图像等各种模式的信息,有望实现更接近人类的人工智能。
前景
大规模语言模型,如 ChatGPT,目前正经历着前所未有的繁荣。人们正在对它们的特性和应用进行大量研究。另一方面,大规模语言模型过于庞大,因此开发起来非常困难。因此,我认为目前自然语言处理研究将沿着大规模语言模型小型化和性能改进的道路前进。除此以外,我相信研究将朝着小型大规模语言模型与多模态信息和机器人强化学习相融合的方向发展,以实现更像人类的人工智能。
给想从事这项研究的人的信息
过去,创建一个机器翻译系统需要花费数年时间,而现在深度学习工具已经发展成熟,可以在大学实验实践中创建。如果你对人工智能、深度学习或自然语言处理感兴趣,请来爱媛大学一起学习和研究。